
VSSFlow নামক নতুন মডেলটি অত্যাধুনিক ফলাফল সহ একটি একক সমন্বিত সিস্টেমের সাথে শব্দ এবং বক্তৃতা তৈরি করার জন্য একটি সৃজনশীল স্থাপত্য ব্যবহার করে। নীচে কিছু ডেমো দেখুন (এবং শুনুন)।
সমস্যা
বর্তমানে, বেশিরভাগ ভিডিও-টু-সাউন্ড মডেল (অর্থাৎ, নীরব ভিডিও থেকে শব্দ তৈরি করতে প্রশিক্ষিত মডেল) বক্তৃতা তৈরিতে তেমন ভাল নয়। একইভাবে, বেশিরভাগ টেক্সট-টু-স্পিচ মডেল অ-স্পীচ শব্দ তৈরি করতে ব্যর্থ হয়, কারণ সেগুলি ভিন্ন উদ্দেশ্যে ডিজাইন করা হয়েছে।
তদ্ব্যতীত, উভয় কাজকে একীভূত করার পূর্বের প্রচেষ্টা প্রায়শই এই ধারণার চারপাশে তৈরি করা হয় যে যৌথ প্রশিক্ষণ কর্মক্ষমতা হ্রাস করে, যার ফলে সেটআপের পৃথক পর্যায়ে বক্তৃতা এবং শব্দ শেখানো হয়, পাইপলাইনে জটিলতা বৃদ্ধি পায়।
এই দৃশ্যের পরিপ্রেক্ষিতে, অ্যাপলের তিনজন গবেষক, চীনের রেনমিন বিশ্ববিদ্যালয়ের ছয়জন গবেষকের সাথে মিলে একটি নতুন এআই মডেল VSSFlow তৈরি করেছেন, যা একই সিস্টেমে নীরব ভিডিও থেকে সাউন্ড এফেক্ট এবং বক্তৃতা উভয়ই তৈরি করতে পারে।
শুধু তাই নয়, তারা যে স্থাপত্যটি তৈরি করেছে তা এমনভাবে কাজ করে যে বক্তৃতা প্রশিক্ষণ একে অপরের সাথে হস্তক্ষেপ করার পরিবর্তে শব্দ প্রশিক্ষণকে উন্নত করে এবং এর বিপরীতে।
সমাধান
সংক্ষেপে, VSSFlow জেনারেটিভ এআই-এর বিভিন্ন ধারণার সুবিধা নেয়, যার মধ্যে ট্রান্সক্রিপ্টগুলিকে টোকেনের সাউন্ড সিকোয়েন্সে রূপান্তর করা এবং ফ্লো-ম্যাচিং দিয়ে শব্দ থেকে শব্দ পুনর্গঠন করা শেখা, যা আমরা এখানে কভার করেছি, মূলত মডেলটিকে দক্ষতার সাথে র্যান্ডম শব্দ দিয়ে শুরু করতে এবং পছন্দসই সংকেত দিয়ে শেষ করার প্রশিক্ষণ।
এটি সব একটি 10-স্তরের আর্কিটেকচারে এমবেড করা হয়েছে যা ভিডিও এবং ট্রান্সক্রিপ্ট সিগন্যালকে সরাসরি অডিও জেনারেশন প্রক্রিয়ায় মিশ্রিত করে, মডেলটিকে একই সিস্টেমের মধ্যে সাউন্ড এফেক্ট এবং বক্তৃতা উভয়ই পরিচালনা করতে দেয়।
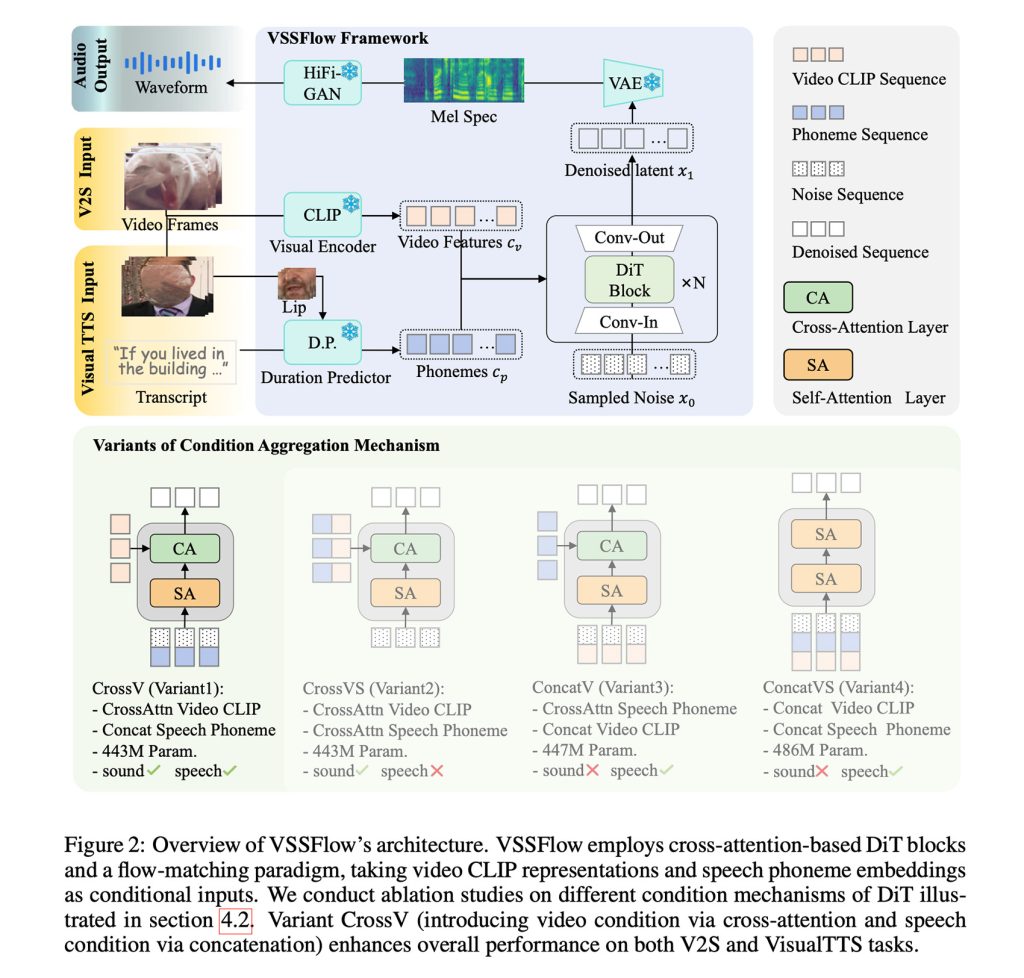
সম্ভবত আরও আকর্ষণীয়ভাবে, গবেষকরা উল্লেখ করেছেন যে বক্তৃতা এবং শব্দের উপর যৌথ প্রশিক্ষণ আসলে উভয় কাজেই ভালো পারফরম্যান্সএর পরিবর্তে উভয়ের মধ্যে প্রতিযোগিতা বা যেকোনো কাজের সামগ্রিক কর্মক্ষমতা হ্রাস।
VSSFlow প্রশিক্ষণের জন্য, গবেষকরা মডেলটিকে পরিবেশগত শব্দ (V2S), ট্রান্সক্রিপ্ট (ভিজ্যুয়াল TTS) এবং টেক্সট-টু-স্পিচ ডেটা (TTS) এর সাথে যুক্ত নীরব কথাবার্তার ভিডিওর মিশ্রণ খাওয়ান, এটি একটি একক এন্ড-টু-এন্ড প্রশিক্ষণ প্রক্রিয়ায় একসাথে সাউন্ড এফেক্ট এবং কথ্য কথোপকথন উভয়ই শিখতে দেয়।
গুরুত্বপূর্ণভাবে, তারা উল্লেখ করেছে যে বাক্সের বাইরে, VSSFlow একই আউটপুটে একই সময়ে স্বয়ংক্রিয়ভাবে পটভূমি শব্দ এবং কথ্য সংলাপ তৈরি করতে সক্ষম হয়নি।
এটি অর্জন করার জন্য, তারা সিন্থেটিক উদাহরণের একটি বড় সেটে তাদের প্রাক-প্রশিক্ষিত মডেলকে পরিমার্জন করেছিল, যাতে বক্তৃতা এবং পরিবেশগত শব্দগুলি একসাথে মিশ্রিত হয়েছিল, যাতে মডেলটি শিখতে পারে যে দুটি একসাথে দেখতে কেমন হওয়া উচিত।
VSSFlowকে কাজে লাগানো হচ্ছে
একটি নীরব ভিডিও থেকে শব্দ এবং বক্তৃতা তৈরি করতে, মডেলটি এলোমেলো শব্দ দিয়ে শুরু হয় এবং পরিবেষ্টিত শব্দগুলিকে আকার দিতে প্রতি সেকেন্ডে 10 ফ্রেমে ভিডিও থেকে ক্যাপচার করা ভিজ্যুয়াল সিগন্যাল ব্যবহার করে৷ উপরন্তু, যা বলা হচ্ছে তার একটি প্রতিলিপি তৈরি করা ভয়েসের জন্য সঠিক নির্দেশনা প্রদান করে।
শুধুমাত্র সাউন্ড এফেক্ট বা শুধুমাত্র বক্তৃতার জন্য নির্মিত টাস্ক-নির্দিষ্ট মডেলগুলির বিরুদ্ধে পরীক্ষা করা হলে, VSSFlow উভয় কাজেই প্রতিযোগিতামূলক ফলাফল প্রদান করে, একটি একক সমন্বিত সিস্টেম ব্যবহার করা সত্ত্বেও বেশ কয়েকটি মূল মেট্রিক্সে প্রান্ত অর্জন করে।
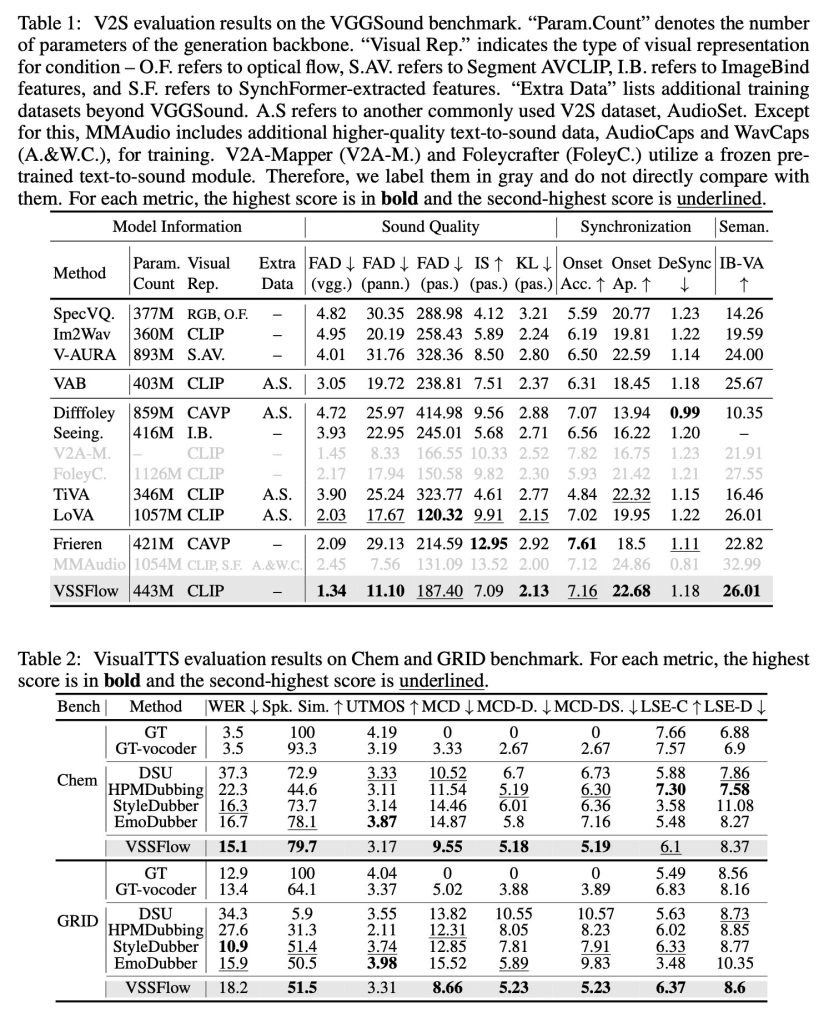
গবেষকরা ভয়েস, বক্তৃতা এবং যৌথ-প্রজন্মের (Veo3 ভিডিও থেকে) ফলাফলের বেশ কয়েকটি ডেমো প্রকাশ করেছেন, পাশাপাশি VSSFlow এবং বেশ কয়েকটি বিকল্প মডেলের মধ্যে তুলনা করেছেন। আপনি নীচের কিছু ফলাফল দেখতে পারেন, তবে সেগুলি দেখতে ডেমো পৃষ্ঠাটি দেখতে ভুলবেন না।
এবং এখানে সত্যিই দুর্দান্ত কিছু: গবেষকরা GitHub-এ ওপেন সোর্সড VSSFlow এর কোড আছে এবং মডেলের ওজন ওপেন সোর্স করার জন্য কাজ করছেন। উপরন্তু, তারা একটি অনুমান ডেমো প্রদানের জন্য কাজ করছে।
পরবর্তীতে কী ঘটতে পারে, গবেষকরা বলেছেন:
এই কাজটি ভিডিও-টু-সাউন্ড (V2S) এবং ভিজ্যুয়াল টেক্সট-টু-স্পীচ (ভিজুয়ালটিটিএস) ফাংশনগুলিকে একীভূত করে একটি ইউনিফাইড ফ্লো মডেল উপস্থাপন করে, যা ভিডিও-কন্ডিশনড শব্দ এবং বক্তৃতা তৈরির জন্য একটি নতুন দৃষ্টান্ত স্থাপন করে। আমাদের কাঠামো ডিআইটি আর্কিটেকচারে বক্তৃতা এবং ভিডিও রাজ্যগুলিকে অন্তর্ভুক্ত করার জন্য একটি কার্যকর রাষ্ট্রীয় একত্রীকরণ প্রক্রিয়া প্রদর্শন করে। তদ্ব্যতীত, আমরা বিশ্লেষণের মাধ্যমে শব্দ-বক্তৃতা যৌথ শিক্ষার পারস্পরিক প্রচারমূলক প্রভাব প্রকাশ করি, সমন্বিত প্রজন্মের মডেলগুলির মান হাইলাইট করে। ভবিষ্যতের গবেষণার জন্য, আরও অন্বেষণের যোগ্য বেশ কয়েকটি দিক রয়েছে। প্রথমত, উচ্চ-মানের ভিডিও-স্পিচ-সাউন্ড ডেটার অভাব ইন্টিগ্রেটেড জেনারেটর মডেলগুলির বিকাশকে সীমাবদ্ধ করে। অতিরিক্তভাবে, শব্দ এবং বক্তৃতার জন্য আরও ভাল উপস্থাপনা পদ্ধতি বিকাশ করা যা কম্প্যাক্ট মাত্রা বজায় রেখে বক্তৃতার বিশদ সংরক্ষণ করতে পারে একটি গুরুত্বপূর্ণ ভবিষ্যতের চ্যালেঞ্জ।
“VSSFlow: যৌথ শিক্ষার মাধ্যমে ভিডিও-কন্ডিশন্ড সাউন্ড এবং স্পিচ জেনারেশনকে একীভূত করা” শিরোনামের অধ্যয়ন সম্পর্কে আরও জানতে এই লিঙ্কটি অনুসরণ করুন।
অ্যামাজনে আনুষঙ্গিক ডিল
![]()
![]()
FTC: আমরা অটো অ্যাফিলিয়েট লিঙ্ক ব্যবহার করি যা আয় করে। আরও


